11. 인식 과정 - 쉼표
쉼표는 쉼표끼리의 공통적인 특성이 없고 직선과 같은 검출하기 쉬운 특징점이 없습니다.
하지만 조표와 음표를 모두 인식 후에 남은 객체들에 한하여 인식 알고리즘을 수행하고
위치가 항상 일정하기 때문에, 크기와 픽셀 개수만으로도 어느 정도 인식이 가능합니다.
음표가 반환되지 않은 객체에 한하여 쉼표 인식 알고리즘을 호출하도록 합시다.
# modules.py
import cv2
import numpy as np
import functions as fs
import recognition_modules as rs
def recognition(image, staves, objects):
key = 0
time_signature = False
beats = [] # 박자 리스트
pitches = [] # 음이름 리스트
for i in range(1, len(objects) - 1):
obj = objects[i]
line = obj[0]
stats = obj[1]
stems = obj[2]
direction = obj[3]
(x, y, w, h, area) = stats
staff = staves[line * 5: (line + 1) * 5]
if not time_signature: # 조표가 완전히 탐색되지 않음 (아직 박자표를 찾지 못함)
ts, temp_key = rs.recognize_key(image, staff, stats)
time_signature = ts
key += temp_key
else: # 조표가 완전히 탐색되었음
notes = rs.recognize_note(image, staff, stats, stems, direction)
if len(notes[0]):
for beat in notes[0]:
beats.append(beat)
for pitch in notes[1]:
pitches.append(pitch)
else:
rs.recognize_rest(image, staff, stats)
cv2.rectangle(image, (x, y, w, h), (255, 0, 0), 1)
fs.put_text(image, i, (x, y - fs.weighted(20)))
return image, key, beats, pitches
# recognition_modules.py
import functions as fs
import cv2
def recognize_rest(image, staff, stats):
x, y, w, h, area = stats
center = fs.get_center(y, h)
rest_condition = staff[3] > center > staff[1]
if rest_condition:
fs.put_text(image, w, (x, y + h + fs.weighted(30)))
fs.put_text(image, h, (x, y + h + fs.weighted(60)))
pass
쉼표는 위치가 항상 고정되어 있다고 했습니다.
어떤 쉼표든지 중심 y좌표가 2번째 오선과 4번째 오선의 사이에 존재합니다.
그리고 크기와 픽셀 개수를 이미지에 찍어보도록 하겠습니다.
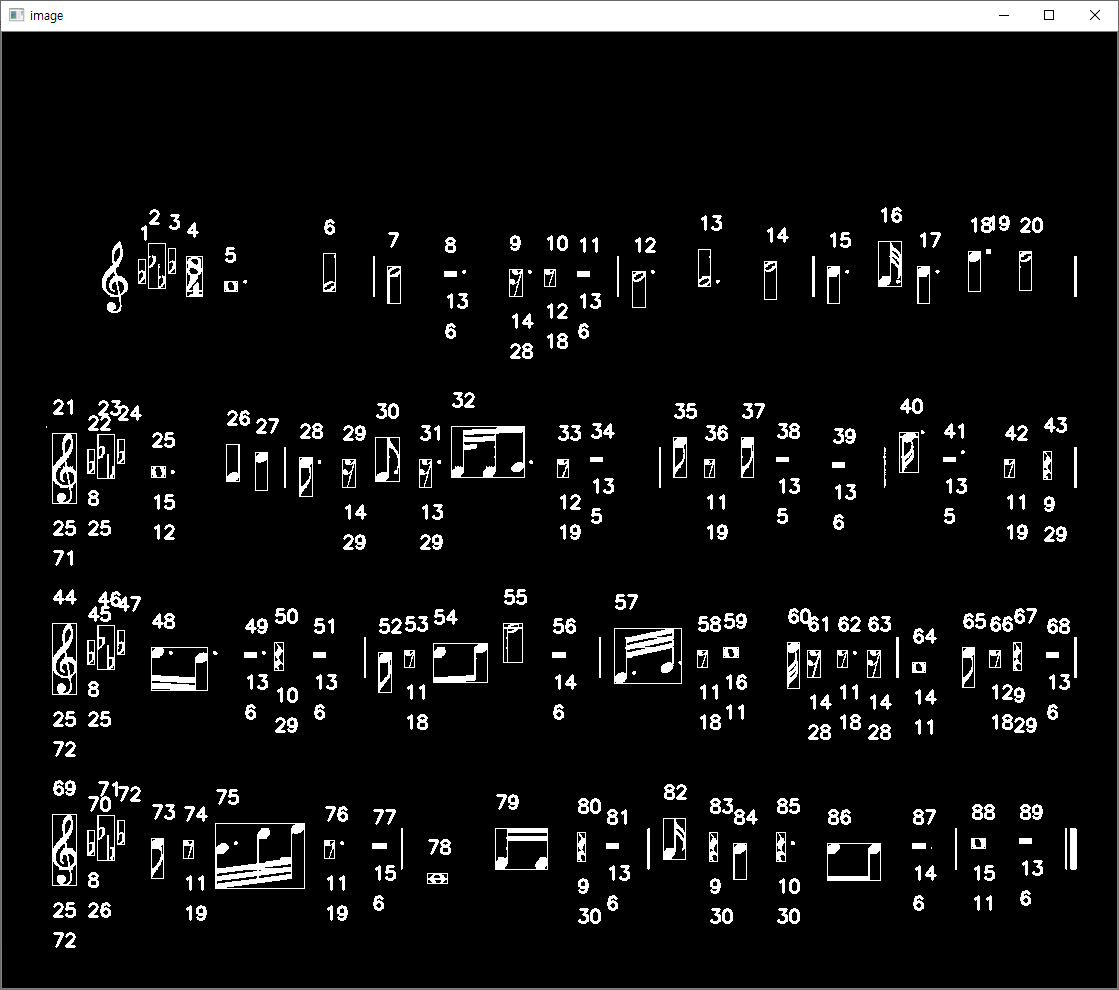
가장 크다고 할 수 있는 16분쉼표의 넓이가 14, 높이가 29~30 정도 입니다.
4분쉼표 정도가 16분쉼표와 높이가 비슷하고 나머지 쉼표들은 확연히 작습니다.
그럼 일정 높이 이상의 쉼표들은 4분쉼표 혹은 16분쉼표라는 뜻이 되고,
일정 높이 미만인 쉼표들은 나머지 쉼표들이 되는 겁니다.
그중 온쉼표와 2분쉼표는 높이가 매우 낮기 때문에, 더 구분하기가 쉽겠죠?
이제 4분쉼표와 16분쉼표를 어떻게 구분할 것이냐인데,
꼬리 개수를 셀 때 썼던 알고리즘을 사용하면 될 것 같습니다.
# recognition_modules.py
import functions as fs
import cv2
def recognize_rest(image, staff, stats):
x, y, w, h, area = stats
center = fs.get_center(y, h)
rest_condition = staff[3] > center > staff[1]
if rest_condition:
cnt = fs.count_pixels_part(image, y, y + h, x + fs.weighted(1))
fs.put_text(image, w, (x, y + h + fs.weighted(30)))
fs.put_text(image, h, (x, y + h + fs.weighted(60)))
fs.put_text(image, cnt, (x, y + h + fs.weighted(90)))
pass
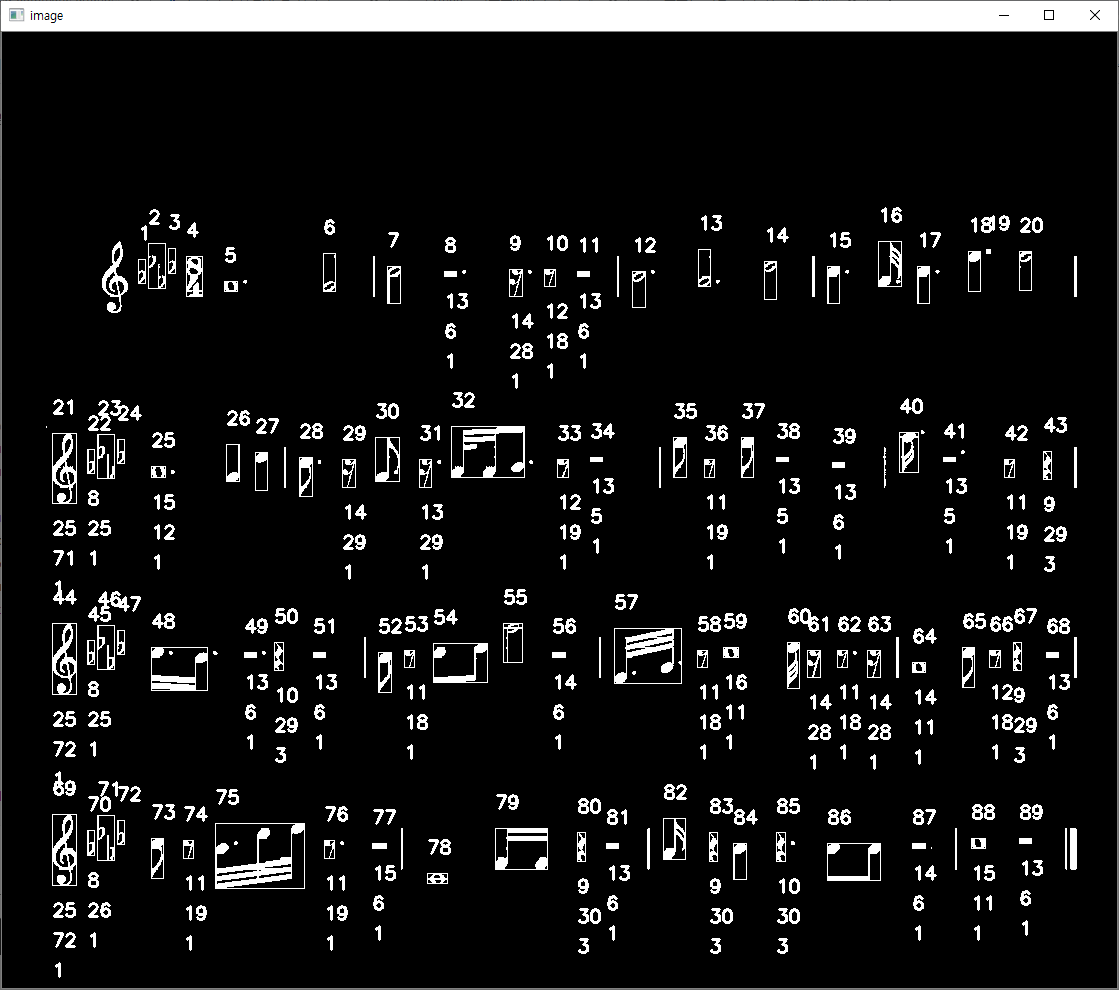
객체의 왼쪽을 탐색하였을 때, 4분쉼표만이 픽셀이 등장하는 부분이 3번인 것을 알 수 있습니다.
그럼 높이가 일정 이상으로 큰 객체인데, cnt가 3이라면 4분쉼표, 아니라면 16분 쉼표로 구분할 수 있을 것 같습니다.
# recognition_modules.py
import functions as fs
import cv2
def recognize_rest(image, staff, stats):
x, y, w, h, area = stats
center = fs.get_center(y, h)
rest_condition = staff[3] > center > staff[1]
if rest_condition:
if h >= fs.weighted(25):
cnt = fs.count_pixels_part(image, y, y + h, x + fs.weighted(1))
if cnt == 3:
fs.put_text(image, "r4", (x, y + h + fs.weighted(30)))
else:
fs.put_text(image, "r16", (x, y + h + fs.weighted(30)))
pass
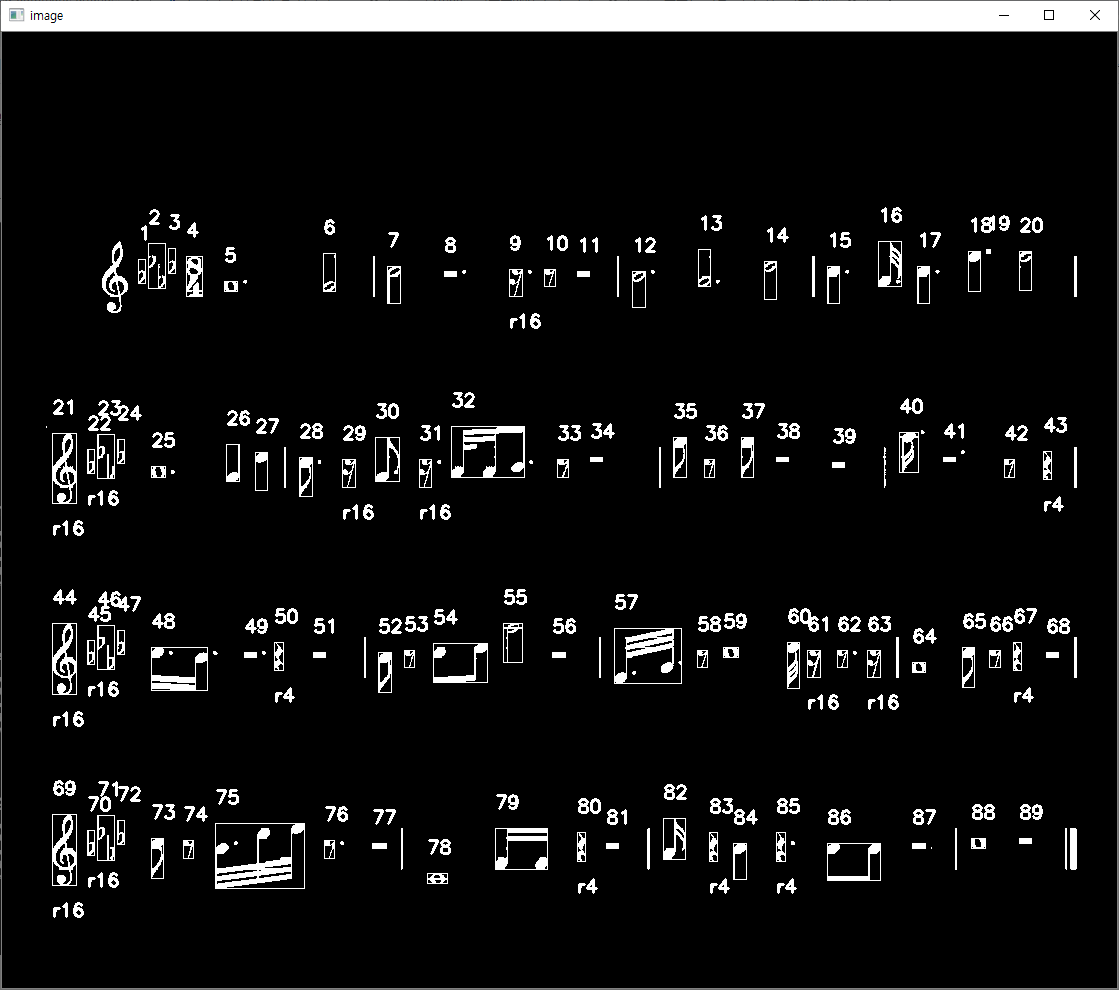
성공적으로 분류된 것을 볼 수 있습니다.
이제 일정 높이 미만의 작은 쉼표들을 분류해보도록 하겠습니다.
먼저 온쉼표와 2분쉼표는 크기가 거의 동일합니다.
하지만 서로 위치가 다르다는 점을 이용해 쉽게 분류가 가능할 것 같습니다.
8분쉼표는 온음표, 온쉼표, 2분쉼표보다는 구분이 가능할 정도로 높이가 있습니다.
# recognition_modules.py
import functions as fs
import cv2
def recognize_rest(image, staff, stats):
x, y, w, h, area = stats
center = fs.get_center(y, h)
rest_condition = staff[3] > center > staff[1]
if rest_condition:
if h >= fs.weighted(25):
cnt = fs.count_pixels_part(image, y, y + h, x + fs.weighted(1))
if cnt == 3:
fs.put_text(image, "r4", (x, y + h + fs.weighted(30)))
else:
fs.put_text(image, "r16", (x, y + h + fs.weighted(30)))
elif fs.weighted(22) >= h >= fs.weighted(16):
fs.put_text(image, "r8", (x, y + h + fs.weighted(30)))
elif fs.weighted(8) >= h:
if staff[1] + fs.weighted(5) >= center >= staff[1]:
fs.put_text(image, "r1", (x, y + h + fs.weighted(30)))
elif staff[2] >= center >= staff[1] + fs.weighted(5):
fs.put_text(image, "r2", (x, y + h + fs.weighted(30)))
pass
대충 조건을 적어보자면 이런 느낌이 되겠네요.
높이에 따라 비슷한 쉼표끼리 묶어 크게 분류하고 다시 정밀한 조건을 주어 분류하였습니다.
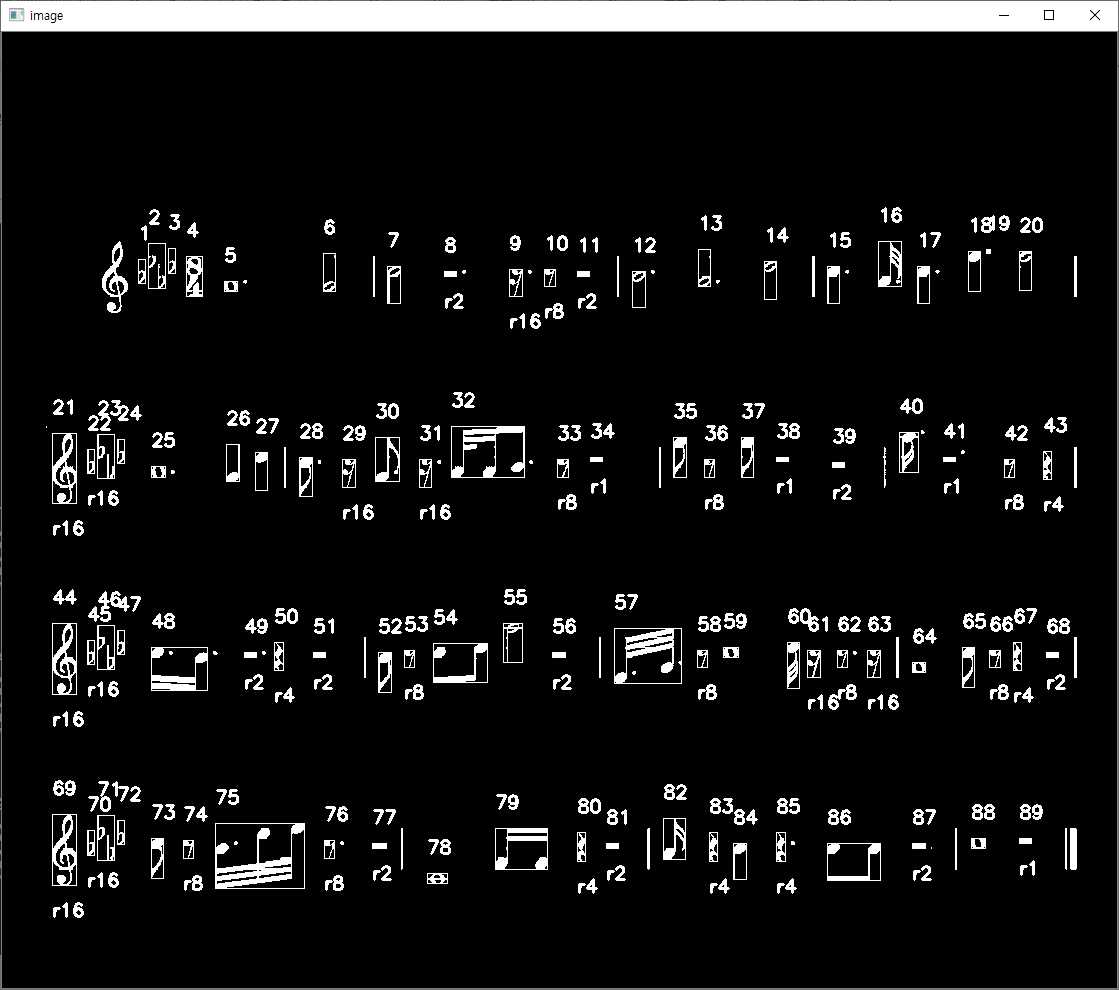
대부분 다 잘 분류되나 16분쉼표로 오인식 되는 객체들이 있습니다.
조금 더 조건을 정밀하게 줘볼게요.
# recognition_modules.py
import functions as fs
import cv2
def recognize_rest(image, staff, stats):
x, y, w, h, area = stats
center = fs.get_center(y, h)
rest_condition = staff[3] > center > staff[1]
if rest_condition:
if fs.weighted(35) >= h >= fs.weighted(25):
cnt = fs.count_pixels_part(image, y, y + h, x + fs.weighted(1))
if cnt == 3 and fs.weighted(11) >= w >= fs.weighted(7):
fs.put_text(image, "r4", (x, y + h + fs.weighted(30)))
elif cnt == 1 and fs.weighted(14) >= w >= fs.weighted(11):
fs.put_text(image, "r16", (x, y + h + fs.weighted(30)))
elif fs.weighted(22) >= h >= fs.weighted(16):
if fs.weighted(15) >= w >= fs.weighted(9):
fs.put_text(image, "r8", (x, y + h + fs.weighted(30)))
elif fs.weighted(8) >= h:
if staff[1] + fs.weighted(5) >= center >= staff[1]:
fs.put_text(image, "r1", (x, y + h + fs.weighted(30)))
elif staff[2] >= center >= staff[1] + fs.weighted(5):
fs.put_text(image, "r2", (x, y + h + fs.weighted(30)))
pass
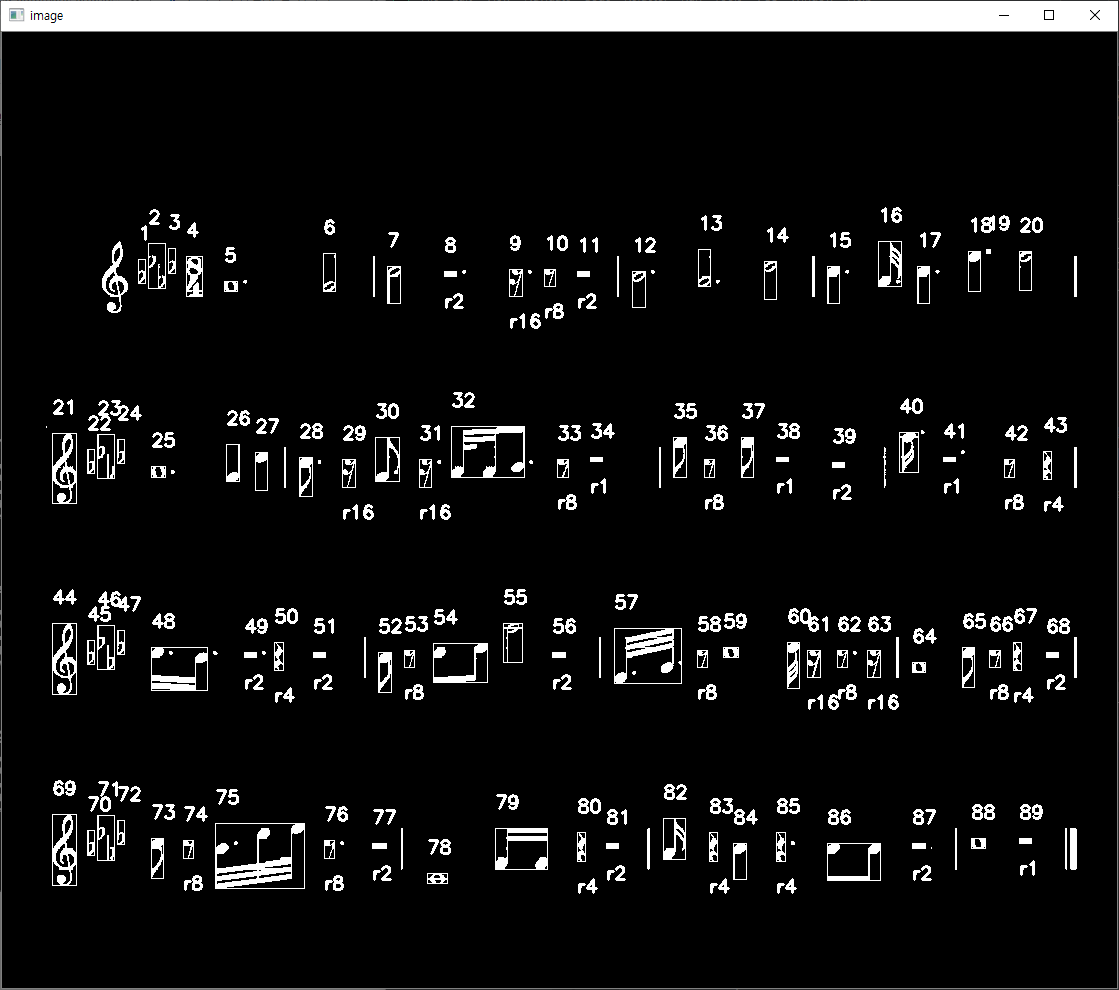
자 이제 모든 쉼표가 분류된 것 같습니다.
이제 점의 유무만 파악해주면 될 것 같은데요.
쉼표는 객체의 오른쪽 부분을 탐색하기만 하면 되기 때문에, 수월할 것 같습니다.
# recognition_modules.py
import functions as fs
import cv2
def recognize_rest(image, staff, stats):
x, y, w, h, area = stats
center = fs.get_center(y, h)
rest_condition = staff[3] > center > staff[1]
if rest_condition:
if fs.weighted(35) >= h >= fs.weighted(25):
cnt = fs.count_pixels_part(image, y, y + h, x + fs.weighted(1))
if cnt == 3 and fs.weighted(11) >= w >= fs.weighted(7):
fs.put_text(image, "r4", (x, y + h + fs.weighted(20)))
elif cnt == 1 and fs.weighted(14) >= w >= fs.weighted(11):
fs.put_text(image, "r16", (x, y + h + fs.weighted(20)))
elif fs.weighted(22) >= h >= fs.weighted(16):
if fs.weighted(15) >= w >= fs.weighted(9):
fs.put_text(image, "r8", (x, y + h + fs.weighted(20)))
elif fs.weighted(8) >= h:
if staff[1] + fs.weighted(5) >= center >= staff[1]:
fs.put_text(image, "r1", (x, y + h + fs.weighted(20)))
elif staff[2] >= center >= staff[1] + fs.weighted(5):
fs.put_text(image, "r2", (x, y + h + fs.weighted(20)))
recognize_rest_dot(image, stats)
pass
역시 먼저 함수를 만들어주고, 탐색 구역과 픽셀 개수를 찍어보도록 하겠습니다.
# recognition_modules.py
import functions as fs
import cv2
def recognize_rest_dot(image, stats):
(x, y, w, h, area) = stats
area_top = y - fs.weighted(10) # 쉼표 점을 탐색할 위치 (상단)
area_bot = y + fs.weighted(10) # 쉼표 점을 탐색할 위치 (하단)
area_left = x + w # 쉼표 점을 탐색할 위치 (좌측)
area_right = x + w + fs.weighted(10) # 쉼표 점을 탐색할 위치 (우측)
dot_rect = (
area_left,
area_top,
area_right - area_left,
area_bot - area_top
)
pixels = fs.count_rect_pixels(image, dot_rect)
fs.put_text(image, pixels, (x, y + h + fs.weighted(60)))
cv2.rectangle(image, dot_rect, (255, 0, 0), 1)
pass
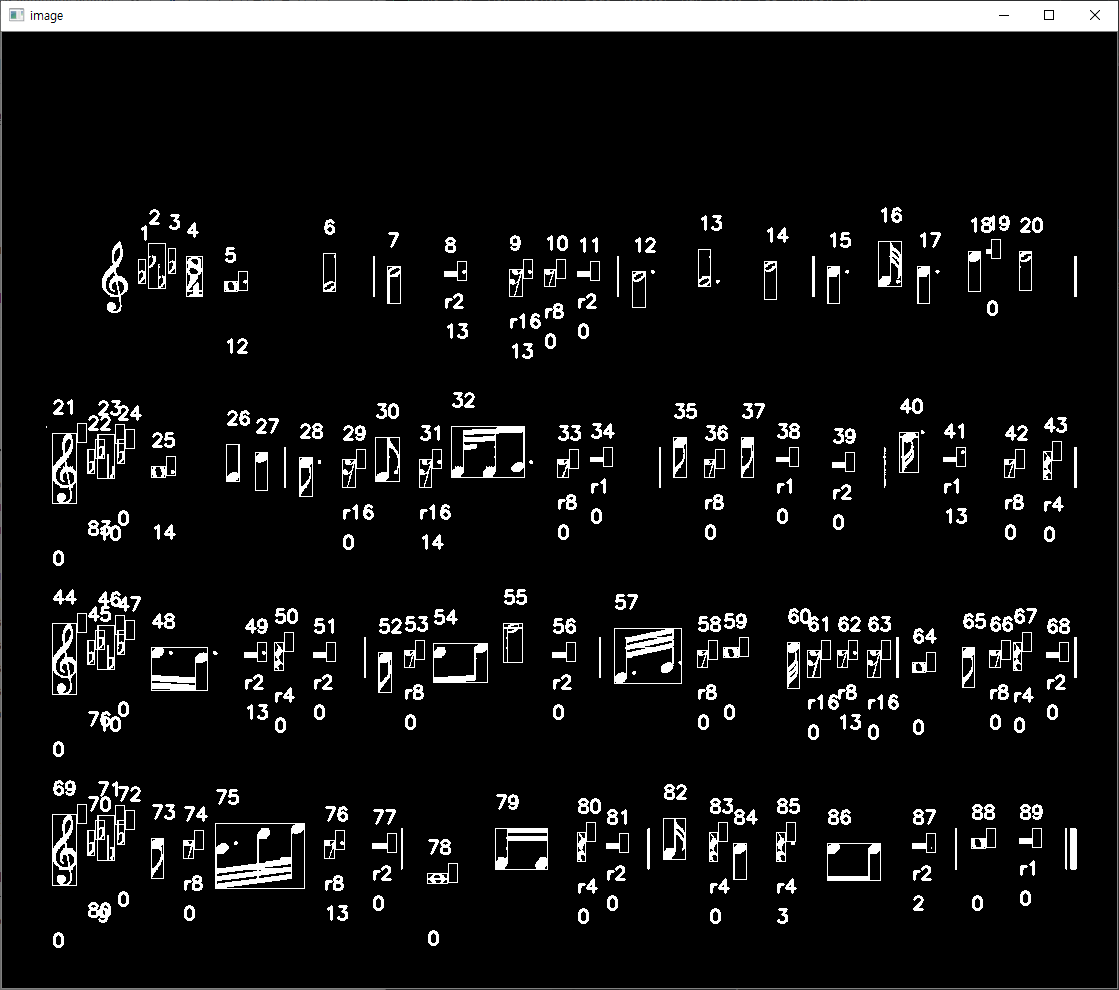
음표와 비슷하게 13~14 정도 나오는 것 같습니다.
# recognition_modules.py
import functions as fs
import cv2
def recognize_rest_dot(image, stats):
(x, y, w, h, area) = stats
area_top = y - fs.weighted(10) # 쉼표 점을 탐색할 위치 (상단)
area_bot = y + fs.weighted(10) # 쉼표 점을 탐색할 위치 (하단)
area_left = x + w # 쉼표 점을 탐색할 위치 (좌측)
area_right = x + w + fs.weighted(10) # 쉼표 점을 탐색할 위치 (우측)
dot_rect = (
area_left,
area_top,
area_right - area_left,
area_bot - area_top
)
pixels = fs.count_rect_pixels(image, dot_rect)
return pixels >= fs.weighted(10)
점의 존재 여부를 반환해주고..
# recognition_modules.py
import functions as fs
import cv2
def recognize_rest(image, staff, stats):
(x, y, w, h, area) = stats
rest = 0
center = fs.get_center(y, h)
rest_condition = staff[3] > center > staff[1]
if rest_condition:
cnt = fs.count_pixels_part(image, y, y + h, x + fs.weighted(1))
if fs.weighted(35) >= h >= fs.weighted(25):
if cnt == 3 and fs.weighted(11) >= w >= fs.weighted(7):
rest = 4
elif cnt == 1 and fs.weighted(14) >= w >= fs.weighted(11):
rest = 16
elif fs.weighted(22) >= h >= fs.weighted(16):
if fs.weighted(15) >= w >= fs.weighted(9):
rest = 8
elif fs.weighted(8) >= h:
if staff[1] + fs.weighted(5) >= center >= staff[1]:
rest = 1
elif staff[2] >= center >= staff[1] + fs.weighted(5):
rest = 2
if recognize_rest_dot(image, stats):
rest *= -1
return rest
쉼표도 반환해주겠습니다.
# modules.py
import cv2
import numpy as np
import functions as fs
import recognition_modules as rs
def recognition(image, staves, objects):
key = 0
time_signature = False
beats = [] # 박자 리스트
pitches = [] # 음이름 리스트
for i in range(1, len(objects) - 1):
obj = objects[i]
line = obj[0]
stats = obj[1]
stems = obj[2]
direction = obj[3]
(x, y, w, h, area) = stats
staff = staves[line * 5: (line + 1) * 5]
if not time_signature: # 조표가 완전히 탐색되지 않음 (아직 박자표를 찾지 못함)
ts, temp_key = rs.recognize_key(image, staff, stats)
time_signature = ts
key += temp_key
else: # 조표가 완전히 탐색되었음
notes = rs.recognize_note(image, staff, stats, stems, direction)
if len(notes[0]):
for beat in notes[0]:
beats.append(beat)
for pitch in notes[1]:
pitches.append(pitch)
else:
rest = rs.recognize_rest(image, staff, stats)
if rest:
beats.append(rest)
pitches.append(-1)
cv2.rectangle(image, (x, y, w, h), (255, 0, 0), 1)
fs.put_text(image, i, (x, y - fs.weighted(20)))
return image, key, beats, pitches
이제 마지막 구성요소 온음표가 남았습니다!
'인공지능 > 컴퓨터비전' 카테고리의 다른 글
| [OpenCV/Python] 악보 인식(디지털 악보 인식) - 12 (5) | 2021.08.08 |
|---|---|
| [OpenCV/Python] 악보 인식(디지털 악보 인식) - 10 (0) | 2021.08.07 |
| [OpenCV/Python] 악보 인식(디지털 악보 인식) - 9 (0) | 2021.08.06 |
| [OpenCV/Python] 악보 인식(디지털 악보 인식) - 8 (0) | 2021.08.06 |
| [OpenCV/Python] 악보 인식(디지털 악보 인식) - 7 (6) | 2021.08.06 |




댓글